Tout a commencé le mercredi 30 juin par un message parfaitement innocent de Max qui nous dit que les disques sont presque pleins :
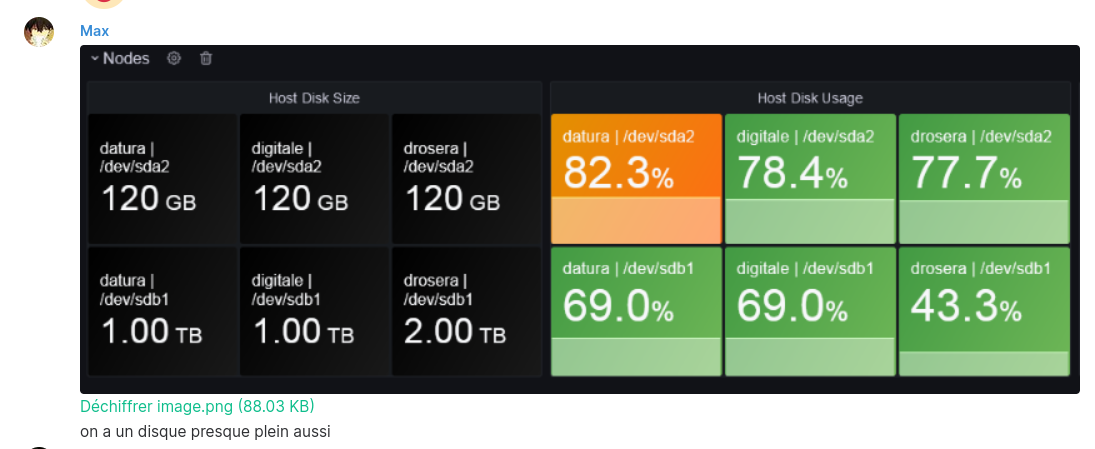
Pour éviter la catastrophe annoncée, je décide de trouver le coupable. Après une rapide recherche, il apparait que PostgreSQL occupe plus de 50Go. Ayant des SSD de 120 Go, c’est donc majoritairement PostgreSQL qui occupe de la place. En creusant plus profondément, c’est la base de donnée de Synapse (le serveur Matrix) qui prend tout cet espace, les autres bases ne comptant que pour quelques kilo-octets.
À ce même moment, nous ne le savions pas encore, mais le réseau Matrix faisait face à une vague de spam. Sans être responsable de l’indisponibilité qui va suivre, elle plante le décor et participe à expliquer pourquoi nous avons été pris de court. En effet, la croissance rapide de notre base de donnée n’est pas seulement due à des usages normaux, mais aussi au spam qui a généré beaucoup d’activité sur les autres serveurs, et via la fédération, participé à remplir notre base.
Pour finir de planter le décor, notre instance Matrix a 4 ans mais n’a jamais nécessité de nettoyage ou maintenance de quelque sorte que ce soit jusqu’ici, bien que jusqu’à récemment, nous nous fédérerions avec des salons bruyants comme Matrix HQ. Nous avons donc aucune expérience dans ce domaine.
Sûr de moi, je vise une petite maintenance de deux heures où je compte supprimer les salons de discussions vides et réduire l’historique distant des salons très bruyants. La documentation sur le sujet est quasi inexistante mais je me dis que c’est parce que la tâche ne doit pas être si complexe. En réalité, la maintenance durera 4 jours et ne se sera pas passée du tout comme prévu. Je vous propose de revenir ici sur tous les points qui ont bloqué !
Avant d’aller plus loin, je souhaite souligner l’existence de deux guides sur le sujet qui m’ont aidé et qui sont de très bons compléments à cet article :
- Compressing Synapse database par Levans
- Administration Synapse > Nettoyage du serveur par Tedomum
L’API d’administration de Synapse
Replaçons le contexte : Matrix est un protocole, et spécifie entre autre des API de communications clients à serveurs et serveurs à serveurs. Cependant, à ce jour, les API de Matrix ne permettent pas à des communautés de se gérer totalement en autonomie. La preuve, nous étions en train d’épuiser les ressources du serveur mais nous pouvions rien faire en tant qu’utilisateur pour les libérer. Au delà de la gestion des ressources, il manque aussi des outils pour la gestion du spam et la modération.
En suivant l’actualité de Matrix, on peut voir qu’ils travaillent déjà sur ces fonctionnalités. Pour la gestion de l’espace disque, ils ont une option pour définir la durée de rétention de l’historique d’un salon de discussion mais l’option n’est pas encore disponible dans l’interface. On sait aussi qu’ils ont échangé avec la Quadrature du Net sur les questions de modération.
En attendant la publication de ces fonctionnalités, les développeurs de Synapse ont déplacé ces responsabilités depuis les utilisateurs vers les administrateurs. Ils fournissent aux administrateurs des fonctionnalités manuelles et naives via une API ne faisant pas partie de la norme Matrix.
J’ai commencé par explorer cette API via l’interface web synapse-admin réalisée par la communauté. Elle m’a permis de supprimer presque un millier de comptes invités et quelques salons de discussions vides. Cependant, cette interface montre vite ses limites : elle est très vite ralentie quand il y a beaucoup de contenu et gèrent très mal les opérations en lot (suppression de 40 salons d’un coup par exemple). Enfin, en affichant par défaut tout le contenu qu’elle a à disposition, elle expose inutilement des données personnelles aux administrateurs.
Très vite, je suis passé en ligne de commande avec curl (pour les requêtes HTTP) et jq (pour intéragir avec le JSON), ce qui semble être une pratique qui fait consensus parmi les administrateurs de serveurs Synapse.
La mise en route est rapide : il faut commencer par passer un compte Synapse en administrateur dans la base de données
UPDATE users SET admin = 1 WHERE name = '@foo:bar.com';
Ensuite, il faut récupérer un bearer pour ce compte. Pour ma part, je me suis simplement connecté sur Element avec puis j’ai utilisé l’inspecteur réseau de mon navigateur, regardé les détails d’une requête partant vers l’API et extrait l’entête Authorization qui contient le bearer.
Enfin, pour ne pas retaper le bearer à chaque fois, je définis un alias pour ma session (il faut remplacer les points d’interogation avec le bearer que vous avez récupéré précédemment !) :
alias mctl='curl --header "Authorization: Bearer ???"'
Vous pouvez commencer par récupérer quelques informations simples comme le nombre de salons et le nombres de comptes sur votre serveur :
mctl 'https://synapse.tld/_synapse/admin/v1/rooms?limit=0'
mctl 'https://synapse.tld/_synapse/admin/v2/users?from=0&limit=0&guests=true'
Maintenant qu’on a le nombre, on va vouloir récupérer la liste. À vous de choisir si vous voulez écrire un script utilisant le système de pagination de l’API ou tout récupérer d’un coup au risque de mettre une pression importante sur votre serveur.
Ayant moins de 10 000 entrées, j’ai tout récupéré d’un coup :
mctl 'https://synapse.tld/_synapse/admin/v1/rooms?limit=10000' > rooms.json
mctl 'https://synapse.tld/_synapse/admin/v2/users?from=0&limit=10000&guests=true' > users.json
J’ai procédé à chaque fois en deux étapes : référencement des objets à supprimer dans un fichier puis appels à l’API. J’ai commencé par les comptes, et plus particulièrement les comptes invités, qui étaient souvent utilisés quelques minutes avant d’être définitivement perdus :
cat users.json \
# requête jq manquante
>> users_to_delete.txt
Ensuite, LX avait développé un bridge entre Synapse et plusieurs autres protocols de communication comme Mattermost, Facebook ou IRC.
Ne nous donnant pas entière satisfaction, nous avons décidé de le décomissioner.
Le bridge devant répliqué un grand nombre de données, il était intéressant de supprimer ses données également.
Étant donné son évolution et ses différents protocoles, nous avons du réaliser plusieurs requetes via jq :
cat users.json \
| jq -r '.users[] | select(.name) | select(.name|test("_ezbr_:deuxfleurs.fr$")) | .name' \
>> users_to_delete.txt
cat users.json \
| jq -r '.users[] | select(.name) | select(.name|test("^@_ezbr_")) | .name' \
>> users_to_delete.txt
Il ne reste plus alors qu’à appeler l’API de Synapse :
cat users_to_delete.txt \
| while read u; do
echo "delete $u"
mctl \
-w "\n%{http_code}\n" \
-X POST \
-H "Content-Type: application/json" \
-d '{"erase": true}' \
https://synapse.tld/_synapse/admin/v1/deactivate/$u
echo -e "done $u\n"
done
Après que mon nettoyage utilisateur soit terminé, je suis passé du côté des salons. J’ai commencé par référencer les salons vides :
cat rooms.json \
| jq -r '.rooms[] | select(.joined_local_members == 0) | .room_id' \
>> rooms_to_delete.txt
Ensuite je me suis occupé de Easybridge : en effet, il ne créait pas seulement des comptes mais aussi des salons. Là aussi, il m’a fallu chercher différents motifs pour repérer les salons, ce qui a nécessité plusieurs requêtes :
cat rooms.json \
| jq -r '.rooms[] | select(.canonical_alias) | select(.canonical_alias|test("_ezbr_:deuxfleurs.fr$")) | .room_id' \
>> rooms_to_delete.txt
cat rooms.json \
| jq -r '.rooms[] | select(.creator) | select(.creator|test("_ezbr_:deuxfleurs.fr$")) | .room_id' \
>> rooms_to_delete.txt
cat rooms.json \
| jq -r '.rooms[] | select(.creator) | select(.creator|test("^@_ezbr_")) | .room_id' \
>> rooms_to_delete.txt
Enfin, bien que nous n’avions pas prévu à l’origine de supprimer des salons auxquelles nous participions encore, il est apparu que certains étaient particulièrement couteux à suivre. Cette information n’est pas disponible via l’API, cependant à l’aide de requêtes SQL plus loin, nous avons déterminé que les 6 salons suivants étaient trop couteux à suivre pour nous (Matrix HQ, Matrix HQ (old), Arch Linux (old), tor, openwrt et fedora-devel) :
cat >> rooms_to_delete.txt <<EOF
!OGEhHVWSdvArJzumhm:matrix.org
!mpvDHdMSZHzhzEDirR:matrix.org
!QtykxKocfZaZOUrTwp:matrix.org
!gVMacPcvhtqaEfaANo:matrix.org
!SEgsRQLScqPxYtucHl:archlinux.org
!MqVoatBTzkpWvekEvo:matrix.org
EOF
Maintenant que notre liste est complète, on peut supprimer les salons (l’API est synchrone) :
cat rooms_to_delete.txt \
| while read r; do
echo -e "delete $r\n"
mctl \
-w "\n%{http_code}\n" \
-X DELETE \
-H "Content-Type: application/json" \
-d '{"purge": true}' \
https://synapse.tld/_synapse/admin/v1/rooms/$r
done
Pour les salons qui restent, nous voulons limiter l’historique des contenus distants (c’est à dire des messages postés par les internautes ayant un compte rattaché à un autre serveur que le notre) à seulement deux mois. Si on veut remonter plus loin, on peut simplement redemander leur historique à leur serveur d’accueil.
Cette fois-ci l’API est asynchrone et on ne veut pas surcharger le serveur : on va surveiller la suppression courante avant d’en lancer une autre. On veut aussi retélécharger la liste des salons avant de commencer car elle a bien changé : on en a supprimé beaucoup juste avant !
mctl 'https://synapse.tld/_synapse/admin/v1/rooms?limit=10000' > rooms.json
# c'est ici qu'on définit le deux mois VVVVVVVVVVVV
export MX_UNIX_TIMESTAMP=$(date +%s%3N --date='TZ="UTC+2" 2 months ago')
cat rooms.json \
| jq -r '.rooms[] | .room_id' \
| while read room; do
JOB_ID=$(mctl -s -X POST -H "Content-Type: application/json" -d "{\"delete_local_events\": false, \"purge_up_to_ts\": $MX_UNIX_TIMESTAMP}" "https://synapse.tld/_synapse/admin/v1/purge_history/$room" | jq -r '.purge_id')
echo Purge $room, job $JOB_ID
while true; do
STATUS=$(mctl -s "https://synapse.tld/_synapse/admin/v1/purge_history_status/$JOB_ID" | jq -r ".status")
echo Purge $room, job $JOB_ID, status $STATUS
if [ "$STATUS" = "complete" ]; then break; fi
if [ "$STATUS" = "null" ]; then break; fi
sleep 10
done
done
Finir par mettre les mains dans le SQL
export PGPASSWORD="???"
alias mpsql='psql -h 127.0.0.1 -U matrix synapse'
Pour avoir une idée de ce “coût”, nous avons du passer par SQL (attention les commandes mettent beaucoup de temps à s’exécuter).
Cette première commande permet d’avoir le nombre ??? Vous pouvez adapter la limite pour afficher plus de
SELECT room_id, count(*) AS count
FROM state_groups_state
GROUP BY room_id
ORDER BY count DESC
LIMIT 6;
-- Result (the last column has been added by me):
-- !OGEhHVWSdvArJzumhm:matrix.org | 51203310 | matrix HQ
-- !mpvDHdMSZHzhzEDirR:matrix.org | 19954563 | tor
-- !QtykxKocfZaZOUrTwp:matrix.org | 14727741 | Matrix HQ
-- !gVMacPcvhtqaEfaANo:matrix.org | 11356723 | fedora-devel
-- !SEgsRQLScqPxYtucHl:archlinux.org | 5326554 | Arch Linux (old)
-- !MqVoatBTzkpWvekEvo:matrix.org | 2961032 | #openwrt
Cette commande est plus rapide, c’est elle aussi qui est utilisée en interne pour calculer une complexité arbitraire pour les salons :
SELECT r.name, s.room_id, s.current_state_events
FROM room_stats_current s
LEFT JOIN room_stats_state r USING (room_id)
ORDER BY current_state_events DESC
LIMIT 6;
; Result:
; Matrix HQ | !OGEhHVWSdvArJzumhm:matrix.org | 57475
; #openwrt | !MqVoatBTzkpWvekEvo:matrix.org | 16083
; Arch Linux (old) | !SEgsRQLScqPxYtucHl:archlinux.org | 15718
; Yggdrasil | !DwmKuvGvRKciqyFcxv:matrix.org | 3462
; Synapse Announcements | !qBFNwucQebGPQldAnq:matrix.org | 2755
; Synapse Announcements | !iyIlInqJyxXrRmRHFx:matrix.org | 2544
Quelques changements de configuration
presence:
enabled: false
limit_remote_rooms:
enabled: true
complexity: 3.0
complexity_error: "Ce salon de discussion a trop d'activité, le serveur n'est pas assez puissant pour le rejoindre. N'hésitez pas à remonter l'information à l'équipe technique, nous pourrons ajuster la limitation au besoin."
admins_can_join: false
retention:
enabled: true
# no default policy for now, this is intended.
# DO NOT ADD ONE BECAUSE THIS IS DANGEROUS AND WILL DELETE CONTENT WE WANT TO KEEP!
purge_jobs:
- interval: 1d
VACUUM FULL et Tablespace, un duo de choc
Un tablespace est un concept dans PostgreSQL qui permet de stocker les données d’une database à un autre emplacement sur le disque. Dans notre cas, on a une configuration avec un petit SSD et un gros HDD. J’ai créé un tablespace sur le HDD pour la base de donnée Synapse, qui avait donc plein d’espace à elle, ce qui m’a permis de lancer un VACUUM FULL.
Quand le WAL te met au pied du mur
PostgreSQL, pour gérer sa réplication, envoie un WAL, Write-Ahead Log. C’est à dire toutes les modifications à faire pour arriver à l’état actuel. Malheureusement il n’y aucun mécanisme de control flow pour gérer ce WAL : autrement dit, la base de donnée ne ralentit pas son travail pour que le WAL reste à une taille constante. On a donc le problème traditionnel des files d’attentes, avec une file qui grandit à une taille infinie. La plupart du temps en réalité ça ne pose pas problème car la base de donnée est moins sollicitée que la vitesse à laquelle elle est capable d’envoyer le WAL. Mais un VACUUM va créer une quantité énorme d’entrée WAL, de l’ordre de la taille de la table qui est nettoyée, et à une vitesse proche de la vitesse théorique du support de stockage, soit plus rapide que le réseau 100Mbit/s que l’on avait dans le cas d’un SSD. Ajouté à ça qu’un des réplicas utilisait un SSD défaillant qui lisait/écrivait à plus que quelques 10Mbit/s, toute tentative de maintenance résultait en un remplissage des SSD avec du WAL…
Stolon : initialisation, mise à jour et subtilités
keeper a besoin de la libc
très facile de flush totalement le cluster : reinit le cluster
import/export sql, le trick de pv :P